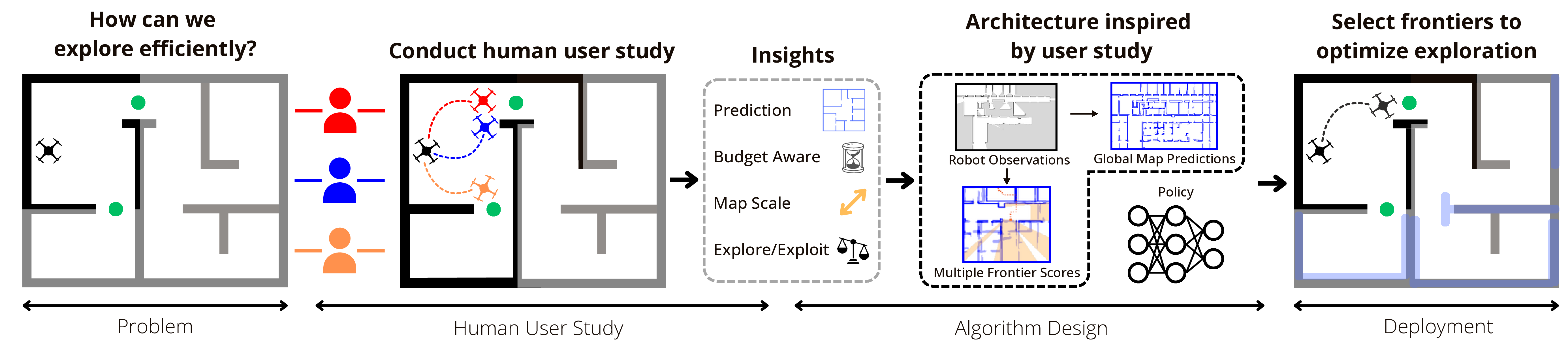
Path planning for robotic exploration is challenging, requiring reasoning over unknown spaces and anticipating future observations. Efficient exploration requires selecting budget-constrained paths that maximize information gain. Despite advances in autonomous exploration, existing algorithms still fall short of human performance, particularly in structured environments where predictive cues exist but are underutilized. Guided by insights from our user study, we introduce MapExRL, which improves robot exploration efficiency in structured indoor environments by enabling longer-horizon planning through a learned policy and global map predictions. Unlike many learning-based exploration methods that use motion primitives as the action space, our approach leverages frontiers for more efficient model learning and longer horizon reasoning. Our framework generates global map predictions from the observed map, which our policy utilizes, along with the prediction uncertainty, estimated sensor coverage, frontier distance, and remaining distance budget, to assess the strategic long-term value of frontiers. By leveraging multiple frontier scoring methods and additional context, our policy makes more informed decisions at each stage of the exploration. We evaluate our framework on a real-world indoor map dataset, achieving up to an 18.8% improvement over the strongest state-of-the-art baseline, with even greater gains compared to conventional frontier-based algorithms.
To design an exploration policy that mirrors human-level decision-making, we first needed to understand how people explore unknown environments. Our motivation was to uncover the long-term strategies, contextual cues, and prioritization methods that humans intuitively use—elements often missing from existing robotic systems.
We conducted a user study where 13 participants of varying robotics experience were tasked with selecting frontiers to explore based on partial map observations and global map predictions. Participants navigated through three different building layouts, attempting to maximize their understanding of the environment within a fixed exploration budget.
Below is a video of one of the participants performing the task.
From the study, we observed that high-performing participants did not simply maximize map coverage—they strategically prioritized exploring uncertain regions in the predicted map, aimed to minimize backtracking, and adapted their strategies based on the map's scale and structure. These behaviors highlighted key decision-making traits like budget awareness, long-horizon planning, and context-driven action selection.
We translated these insights into the design of our RL policy by:
These human-inspired elements allowed our policy to outperform existing methods, especially in complex and large-scale environments.
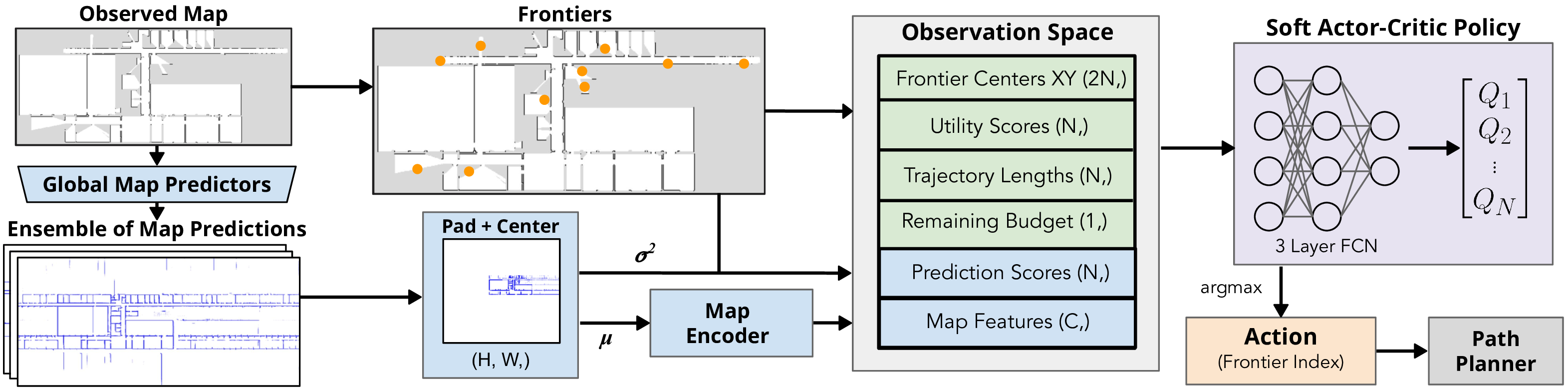
Observed maps are processed through three independent global map prediction models, generating prediction maps. These maps are averaged and passed through a convolutional encoder to extract a 256-dimensional feature vector. This vector is concatenated with frontier centers, prediction and utility scores, distances from the agent, and remaining budget. The resulting vector is fed into a fully connected network that outputs N values, and the argmax is selected as the index of the frontier action.

Table II. Summary of results reported in the paper. Average and 95% confidence interval for reward and IoU on the test maps. Each map includes 15 experiments from different starting positions, totaling 75 experiments across 5 maps. For detailed methodology, analysis, and information about the maps and baseline methods, refer to the full paper.
@article{harutyunyan2025mapexrl,
title={MapExRL: Human-Inspired Indoor Exploration with Predicted Environment Context and Reinforcement Learning},
author={Harutyunyan, Narek and Moon, Brady and Kim, Seungchan and Ho, Cherie and Hung, Adam and Scherer, Sebastian},
booktitle = {2025 22nd International Conference on Advanced Robotics (ICAR)},
journal={arXiv preprint arXiv:2503.01548},
year={2025}
}